Here is the Tech Stack I Used To Create TopMusic
As well as a few thoughts on using AI for coding

TopMusic, my music recommendation app, is now available for download on iOS here and available on web here. It leverages Apple Music and hundreds of year-end lists to give you music recommendations based on artist, genre, year, and even custom prompts. Find the best jazz albums of 2025, find music similar to Charli XCX, or create a playlist of contemplative indie rock to drive to in the morning.
Try it today! I’m sure you’ll find something new that you love. I wrote about my motivations for creating TopMusic here.
I’ve had a few requests to do a write-up on the tech stack I’m using for TopMusic. I’ve been working on this project on-and-off for close to three years now, and this is a good chance to reflect on the evolution of the app, the evolution of its tech stack, and the evolution of using AI towards completing coding tasks.
I’ve started and stopped on numerous side projects before, but I felt committed to finish this one, both because it was something I was genuinely interested in using myself but also because I just wanted to finish something. Of course I kept moving the goalposts for what ‘finish’ entailed: first it was deploying a cloud-hosted web app, then it was deploying a self-hosted web app, then it was adding a recommendation engine on the backend, then it was adding a mobile app, and in the future it will be adding a personalized recommendation component.
My background: I started working as a data scientist back in 2017 and have pivoted to more analytics engineering and data engineering work since 2022. I’ve created a few dummy applications via Streamlit that were hosted on Streamlit or Heroku but have never self-hosted a website and never designed a mobile app1.
I have the background of a Type 2 engineer — someone who learned specific tools and technologies rather than learning computer science in depth. Is this a bad thing? I think it depends on the context. For creating a new, relatively simple product it’s certainly speedier to learn what you need, get feedback, and iterate. For growing a more mature product there may be a point where tech debt accumulates or certain assumptions break and you need to work back from first principles. I do plan on working through Designing Data-Intensive Applications, but I think it will be a much richer experience with the context of my app in mind.
This bifurcation is of course thrown out of whack when you introduce AI as a tool that ostensibly can build code for anyone regardless of their experience. I’ve heard horror stories about companies with executive mandates to build code with AI and fear both for the executives who think they can replace their engineering team and the engineers who have to deal with the eventual fallout. I think AI can be extraordinarily helpful with the right intentions — more on this below — but the first rule on having access to build should be understanding the drawbacks and complications of what you can build.
In any case I hope this can be useful for anyone not from an engineering-first background looking to build something. TopMusic’s tech stack isn’t that complicated, but it felt much more daunting looking from the outside in. It’s easier to build than ever, but no less rewarding.
Tech Stack
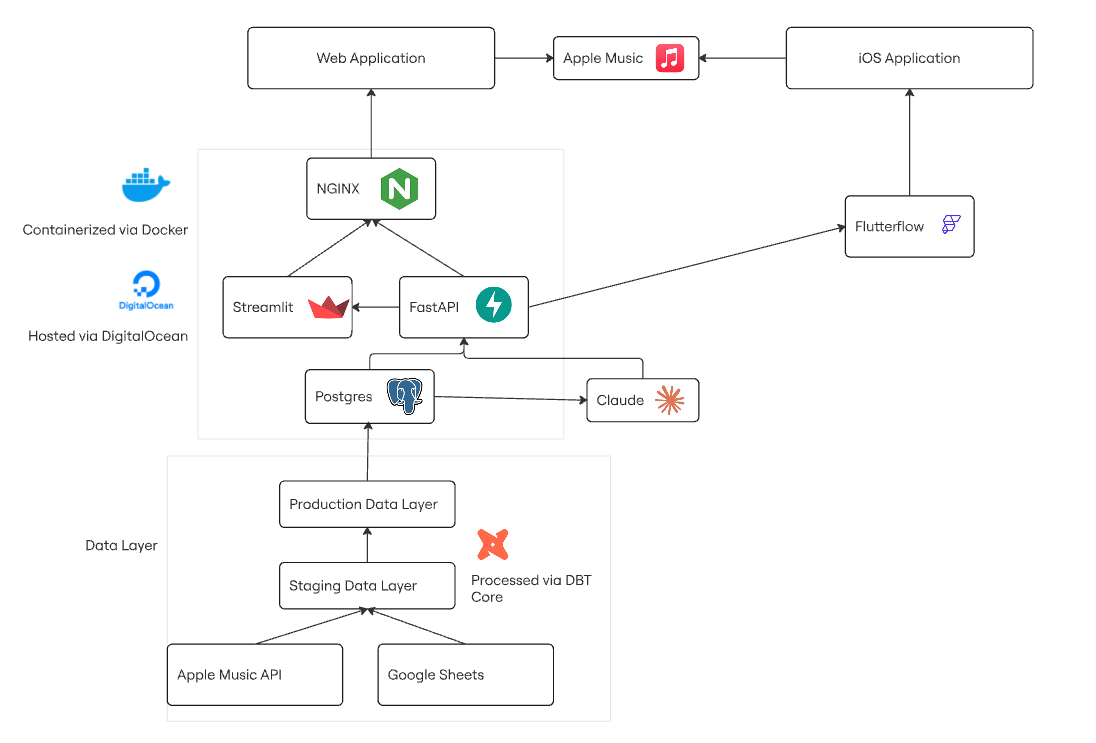
Above is the tech stack I’m currently using. My general philosophy has been to not overthink any decisions and not let perfect be the enemy of the good. The app is small, the userbase is low, and any problem can be addressed.
Data Layer
Google Sheets
TopMusic started as a pretty simple application, using a few CSVs downloaded out of Google Sheets, manipulating them through Pandas, using Streamlit as a frontend, and hosting the Streamlit page via Heroku. It’s dramatically evolved past that, but I still use Google Sheets as my initial input layer for tracking lists from music publications. Note that my data is relatively small — around 11 MB if I download it as an Excel file. The UI is great, the functions work as well as they ever did, it’s easy to do basic QA checks with, and it’s easy to get data in and out of (either via API or just downloading and uploading CSVs as sheets). It’s worth noting that everything I’m doing right now is via batch, such as updating this sheet when a new “Best Of” list comes out.
Apple Music API
I programmatically hit the Apple Music API to get metadata on any new albums that come into the database. The documentation is OK, and the authentication is a little funky, but it’s been basically seamless to work with. I also use this on a batch basis whenever there are new albums added to the database.
DBT Core
I use DBT to take the raw files that live in both my database and Google Sheets and manipulate them as I need to move my data from a staging layer to production layer. It’s an industry standard and remains easy as ever for shaping, testing, and modeling your data with basically any database. Despite the FiveTran acquisition I’m optimistic that the basic functionality of DBT Core will remain intact as an open-source product. Worst case, there will be plenty of forks out there that do the same thing.
Postgres
I didn’t want to think too much about which database to use — the data as it exists is relatively small and will likely remain that way. Postgres is an industry standard, and the pgvector extension is remarkably efficient in doing distance calculations, which is helpful for coming up with ‘similar’ songs or albums. Using pgvector was probably something like a 50-100x speed improvement compared to pulling down the data and doing these calculations via NumPy.
Cloud Hosting/Deployment
DigitalOcean
This is probably a personal preference — I was originally using Heroku but migrated to DigitalOcean due to better cost for my app size with the same features and less code abstraction. I’m using a droplet in DigitalOcean and using their hosted Postgres database — it’s very easy to use with Docker and there are plenty of options if I need a bigger droplet or more sophisticated features (monitoring, load balancing) in the future.
Backend Infrastructure
Docker
Another industry standard — Docker’s made it very easy to containerize my environment, test changes locally, and ship to the cloud with confidence that my cloud environment will run like my local environment. I’ve been using Docker Compose to manage the relationships between my frontend, backend, and reverse proxy. While this was initially a pain to set up, it is now very easy to debug and edit with AI.
FastAPI
FastAPI is my choice for creating API endpoints that hit my database. I used Django previously and found FastAPI much easier to get a handle on. The documentation is fantastic and it’s been really helpful as I’ve been developing more ‘advanced’ features like utilizing middleware and returning HTML templates.
NGINX
NGINX is a reverse proxy that lets me serve my Docker container on my website, letting me serve multiple ports (Streamlit, FastAPI, static web pages) on an HTTPS site without issue. This was something I knew zero about previously.
Claude
When I originally wanted to turn keyword prompts into playlists (e.g. ‘make me a playlist of quiet jazz for studying’), I thought it would make sense to run a self-hosted open-source AI (Ollama) inside my container for cost reasons. This was technically feasible —and reasonable enough to set up — but way too expensive due to hardware reasons: a reserved GPU droplet on DigitalOcean is $2/hour or ~$1,500/month. Trying to run Ollama via CPU is technically feasible but takes long enough to run (minutes) that the request gets timed out.
Meanwhile Claude Haiku costs $1 per million tokens for input and $5 per million tokens for output. My requests usually have around ~800 tokens of input and ~200 tokens of output, so $0.0018 per request that comes back in 2-5 seconds. No brainer.
There may be better on-demand options that I’m not aware of, but this is cheap enough for now.
Frontend Infrastructure
Streamlit
I’ve been using Streamlit for a few years now as a means of creating frontend applications via Python. It has its pros and cons; while it’s relatively easy to pick up and can be done entirely in Python, it has limited design functionality. I often joke that Streamlit pages look like websites designed by data scientists.
I’d say that Streamlit is good for building your first website but not sure if I’d recommend it beyond that. Everything works — even an OAuth flow that goes through Apple Music — but it definitely feels a little sub-standard.
Flutterflow
Before vibecoding there were no-code applications. When I wanted to create an iOS app for TopMusic, Flutterflow was a safe choice for designing a relatively simple iOS app without having to learn Swift.
The learning curve for getting used to Flutterflow was probably the most difficult part of this entire process, both in thinking about the UX of the app (something I’ve never seriously considered before despite spending seemingly my entire life browsing apps), as well as successfully containerizing all of the elements on a given screen and having it come out as intended.
There’s plenty of documentation and video tutorials out there, but the time spent ingesting these can add up, and while there is a community forum for issues not covered by their documentation, it’s hit-or-miss. Many posts were filled with people asking similar questions to what I searched and giving up, concluding that Flutterflow couldn’t solve their problem.
There were also edge cases where I needed to write Dart code to create custom functions — this was originally quite daunting and annoying but has been made much easier through AI.
Where Flutterflow is potentially most helpful is in testing and deployment. I can test changes locally on a browser or my phone (via Xcode), as well as seamlessly deploy to the App Store when ready. I’ve only deployed on iOS thus far, but it gives me the option to deploy to Android in the future.
Future Considerations
Personalized Recommendations
The next step with TopMusic is to add personalized recommendations. If you listen to jazz and hip-hop, I want the app’s homepage to show you jazz and hip-hop recommendations without you having to seek them out yourself. This is reasonably easy to do from a data standpoint — it’s only utilizing one or two more endpoints from the Apple Music API. But the process is slow due to data limits from Apple’s end, meaning that the endpoints need to be hit several times each. This process would probably take at least 10 seconds. It’s a good excuse to set up a service where I pull listening history from every (active?) user at a regular interval and store it so it can be fetched later.
Better Monitoring and Logging
I have very high-level monitoring on DigitalOcean to make sure that the actual droplet is working, but nothing logging when different APIs are hit and monitoring whether there are any issues. Very interested in exploring what options are out there.
Costs
Right now my costs are:
$99/year for Apple Developer Program membership
$87/month for DigitalOcean droplet and database
$49/month for Flutterflow
$0.0018/request for Claude. If this hits $5/month I will be extremely happy with how the app has grown.
How I Use AI
I’ll be honest — it’s hard for me to get a gauge of how data people and engineers are actually using AI at the moment2. Perhaps this is a me problem, and my perception of AI usage feels distorted because I bother to look at the AI hucksters posting on LinkedIn or the Everything App. Perhaps it’s also because AI is evolving so rapidly that its widespread application today is likely different than it was even six months ago. If I were to guess the breakout of how AI is being used right now3 by data people and engineers, I’d say:
20% of people are not using AI at all for coding, or using it for simple autocompletion
60% of people are using it for ad-hoc requests, via UI chat, IDE, and/or the command line
20% of people are letting it rip with tools like Claude Code, letting it create or re-write entire repos or even more
But I have no idea, truthfully! I wouldn’t be surprised if this distribution swung wildly one way or the other.
Currently I fall squarely into the second bucket. My AI approach is:
Prompting Claude with a specific question for a problem I have (e.g. “How do I add a static web page to a Docker container”), having it return the necessary functions, and then manually adding those functions to my repo.
Using Cursor to troubleshoot specific functions or lines of code, having AI test that its updated suggestions work.
In this context, AI has been unequivocally helpful in completing tasks faster. Setting up my reverse proxy correctly or creating custom functions in Flutterflow went from taking days to hours or minutes with the support of Claude. I thought that turning custom prompts into playlists would be a v2 feature for the app, something that would take months to deploy. It took about a week.
And yet, I suspect my approach to using AI for code is probably still too conservative. I’m not using Claude Code for high-level requests on my repos. I’ve never used an agent. There’s some nasty tech debt in my repo and I’m a little afraid of breaking something if I’m unclear of the changes it has proposed. I’m looking forward to using these tools when I can start on something from scratch — I’ve heard Claude Code is excellent.
The limitations I’ve come across have been from asking AI tactical questions. For example, when I asked Claude to give me recommendations on using an open-source AI model versus paying for Claude’s API endpoint, it advised me to use Ollama and host it locally, leading me down a rabbit hole of integrating Ollama into my infrastructure before realizing what the GPU costs would be4. And when I had it give me recommendations for building out an OAuth flow for Apple Music, it only acknowledged that it made up the Apple Music endpoints it was referencing when I told it I couldn’t find the endpoints in Apple’s documentation.
For now, my philosophy is that AI is only as good as the feedback loop is. For coding I can very quickly test whether something it created works. For more tactical recommendations with a longer feedback loop I need to be either a little more wary of its recommendations or implement a means of testing its recommendations more rapidly.
As more people use the app, I would love any feedback on your experience — what you enjoy, what you don’t understand, what you would like to see changed and what you would like to see added.
Anticipating the ‘we can tell’ response here.
There are also considerations like company-wide usage of AI for code linting or reviewing pull requests — not considering that here.
Based on very limited anecdotes, to be clear.
Naturally when I called this out, it told me I was correct and complimented me for pointing this out.
Hey, great read as always. It's really interesting how you kept moving the goalpost, and it makes me wonder if the advancements in AI and its integration into coding tasks might actually amplify that tendency for many of us, enabling us to envision and implement increasingly complex features without the usual blockers. There’s a deep satisfaction in seeing a personal project through to completion, especially one that evolves so much, and that self-imposed drive is truely admirable.